


pdf 文档的布局是固定的,不允许用户对其进行修改。如果您想让 pdf 文档内容再次可编辑,可以将 pdf 转换为 word 或直接从 pdf 中提取文本。本文将分为以下三个部分介绍如何使用 spire.pdf for .net 在 c# 和 vb.net 中提取 pdf 文档中的文本。
安装 spire.pdf for .net
首先,您需要添加 spire.pdf for .net 包中包含的 dll 文件作为 .net 项目中的引用。dll 文件可以从此链接下载或通过 安装。
pm> install-package spire.pdf从特定 pdf 页面中提取文本
spire.pdf for .net 提供了 pdftextextractor.extracttext() 方法,可供开发人员直接从 pdf 文档中提取文本。详细步骤如下。
- 创建一个 pdfdocument 对象。
- 使用 pdfdocument.loadfromfile() 方法加载 pdf 文件。
- 通过 pdfdocument.pages[index] 属性获取特定页面。
- 创建一个 pdftextextractor 对象。
- 创建一个 pdftextextractoptions 对象,并将 isextractalltext 属性设置为 true。
- 使用 pdftextextractor.extracttext() 方法从所选页面中提取文本。
- 将提取的文本写入 txt 文件。
- c#
- vb.net
using system.io;
using spire.pdf;
using spire.pdf.texts;
namespace extracttextfrompage
{
class program
{
static void main(string[] args)
{
//创建一个 pdfdocument 对象
pdfdocument doc = new pdfdocument();
//加载pdf文件
doc.loadfromfile("ai数字人.pdf");
//获取指定页面
pdfpagebase page = doc.pages[1];
//创建一个pdftextextractot 对象
pdftextextractor textextractor = new pdftextextractor(page);
//创建一个 pdftextextractoptions 对象
pdftextextractoptions extractoptions = new pdftextextractoptions();
//将 isextractalltext 设置为true
extractoptions.isextractalltext = true;
//从所选页面中提取文本
string text = textextractor.extracttext(extractoptions);
//将提取的文本写入 txt 文件
file.writealltext("提取指定页面文本.txt", text);
}
}
}imports system.io
imports spire.pdf
imports spire.pdf.texts
namespace extracttextfrompage
friend class program
private shared sub main(byval args as string())
'创建一个 pdfdocument 对象
dim doc as pdfdocument = new pdfdocument()
'加载pdf文件
doc.loadfromfile("ai数字人.pdf")
'获取指定页面
dim page as pdfpagebase = doc.pages(1)
'创建一个pdftextextractot 对象
dim textextractor as pdftextextractor = new pdftextextractor(page)
'创建一个 pdftextextractoptions 对象
dim extractoptions as pdftextextractoptions = new pdftextextractoptions()
'将 isextractalltext 设置为true
extractoptions.isextractalltext = true
'从所选页面中提取文本
dim text as string = textextractor.extracttext(extractoptions)
'将提取的文本写入 txt 文件
file.writealltext("提取指定页面文本.txt", text)
end sub
end class
end namespace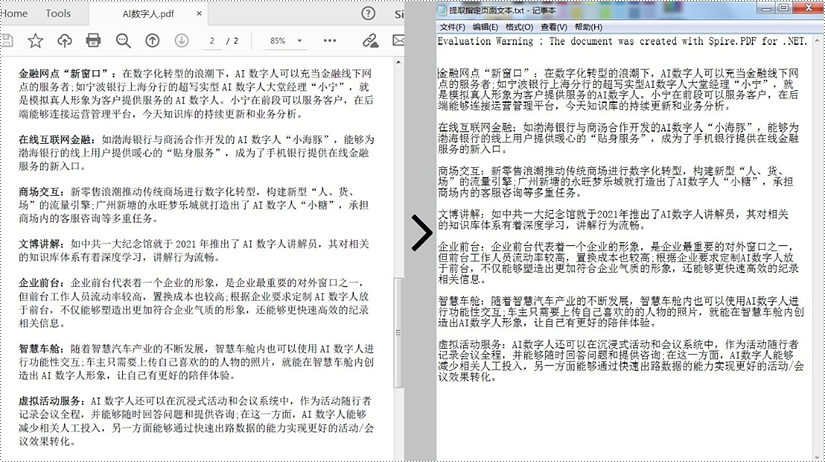
从特定矩形区域中提取文本
如果您需要从指定区域中提取 pdf 文本,可以通过 extractarea 属性指定矩形区域范围,并使用 pdftextextractor.extracttext() 方法从指定区域中提取文本。详细步骤如下。
- 创建一个 pdfdocument 对象。
- 使用 pdfdocument.loadfromfile() 方法加载 pdf 文件。
- 通过 pdfdocument.pages[index] 属性获取特定页面。
- 创建一个 pdftextextractor 对象。
- 创建一个 pdftextextractoptions 对象,并通过它的 extractarea 属性指定矩形区域。
- 使用 pdftextextractor.extracttext() 方法从指定区域中提取文本。
- 将提取的文本写入 txt 文件。
- c#
- vb.net
using spire.pdf;
using spire.pdf.texts;
using system.io;
using system.drawing;
namespace extracttextfromrectanglearea
{
class program
{
static void main(string[] args)
{
//创建一个 pdfdocument 对象
pdfdocument doc = new pdfdocument();
//加载pdf文件
doc.loadfromfile("ai数字人.pdf");
//获取指定页面
pdfpagebase page = doc.pages[1];
//创建一个 pdftextextractot 对象
pdftextextractor textextractor = new pdftextextractor(page);
//创建一个 pdftextextractoptions 对象
pdftextextractoptions extractoptions = new pdftextextractoptions();
//设置矩形区域范围
extractoptions.extractarea = new rectanglef(0, 0, 870, 150);
//从指定区域中提取文本
string text = textextractor.extracttext(extractoptions);
//将提取的文本写入 txt 文件
file.writealltext("特定区域提取文本.txt", text);
}
}
}imports spire.pdf
imports spire.pdf.texts
imports system.io
imports system.drawing
namespace extracttextfromrectanglearea
friend class program
private shared sub main(byval args as string())
'创建一个 pdfdocument 对象
dim doc as pdfdocument = new pdfdocument()
'加载pdf文件
doc.loadfromfile("ai数字人.pdf")
'获取指定页面
dim page as pdfpagebase = doc.pages(1)
'创建一个 pdftextextractot 对象
dim textextractor as pdftextextractor = new pdftextextractor(page)
'创建一个 pdftextextractoptions 对象
dim extractoptions as pdftextextractoptions = new pdftextextractoptions()
'设置矩形区域范围
extractoptions.extractarea = new rectanglef(0, 0, 870, 150)
'从指定区域中提取文本
dim text as string = textextractor.extracttext(extractoptions)
'将提取的文本写入 txt 文件
file.writealltext("特定区域提取文本.txt", text)
end sub
end class
end namespace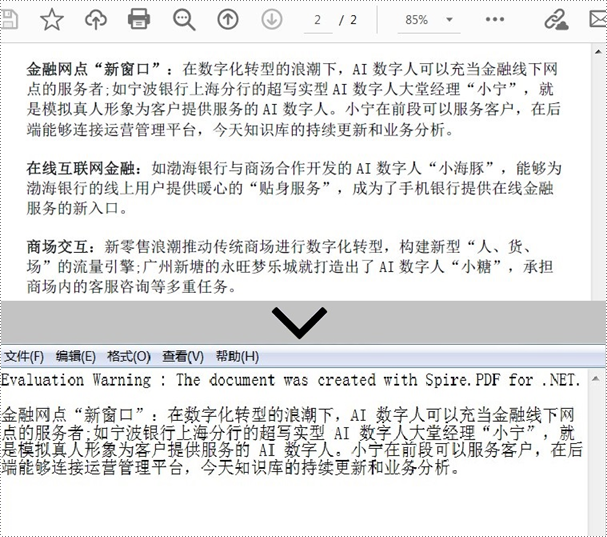
通过 simpletextextractionstrategy 提取文本
上述方法为逐行提取文本。如果使用 simpletextextractionstrategy 提取文本,它会跟踪每个字符串当前的 y 轴位置,并在 y 轴位置发生变化时在输出中插入换行符。详细步骤如下。
- 创建一个 pdfdocument 对象。
- 使用 pdfdocument.loadfromfile() 方法加载 pdf 文件。
- 通过 pdfdocument.pages[index] 属性获取特定页面。
- 创建一个 pdftextextractor 对象。
- 创建一个 pdftextextractoptions 对象并将 issimpleextraction 属性设置为 true。
- 使用 pdftextextractor.extracttext() 方法从所选页面中提取文本。
- 将提取的文本写入 txt 文件。
- c#
- vb.net
using system.io;
using spire.pdf;
using spire.pdf.texts;
namespace simpleextraction
{
class program
{
static void main(string[] args)
{
//创建一个 pdfdocument 对象
pdfdocument doc = new pdfdocument();
//加载pdf文件
doc.loadfromfile("示例文件.pdf");
//获取指定页面
pdfpagebase page = doc.pages[0];
//创建一个 pdftextextractor 对象
pdftextextractor textextractor = new pdftextextractor(page);
//创建一个 pdftextextractoptions 对象
pdftextextractoptions extractoptions = new pdftextextractoptions();
//将 issimpleextraction 设置为true
extractoptions.issimpleextraction = true;
//从指定页面提取文本
string text = textextractor.extracttext(extractoptions);
//将提取的文本写入 txt 文件
file.writealltext("提取文本.txt", text);
}
}
}imports system.io
imports spire.pdf
imports spire.pdf.texts
namespace simpleextraction
friend class program
private shared sub main(byval args as string())
'创建一个 pdfdocument 对象
dim doc as pdfdocument = new pdfdocument()
'加载pdf文件
doc.loadfromfile("示例文件.pdf")
'获取指定页面
dim page as pdfpagebase = doc.pages(0)
'创建一个 pdftextextractor 对象
dim textextractor as pdftextextractor = new pdftextextractor(page)
'创建一个 pdftextextractoptions 对象
dim extractoptions as pdftextextractoptions = new pdftextextractoptions()
'将 issimpleextraction 设置为true
extractoptions.issimpleextraction = true
'从指定页面提取文本
dim text as string = textextractor.extracttext(extractoptions)
'将提取的文本写入 txt 文件
file.writealltext("提取文本.txt", text)
end sub
end class
end namespace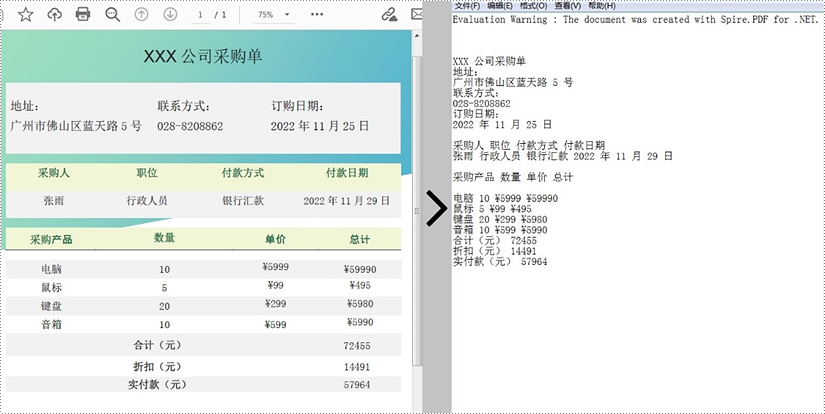
申请临时 license
如果您希望删除结果文档中的评估消息,或者摆脱功能限制,请该email地址已收到反垃圾邮件插件保护。要显示它您需要在浏览器中启用javascript。获取有效期 30 天的临时许可证。


